|
OpenCV 4.12.0
開源計算機視覺
|
載入中...
搜尋中...
無匹配項
上一篇教程: 非線性可分資料的支援向量機
| 原始作者 | Theodore Tsesmelis |
| 相容性 | OpenCV >= 3.0 |
在本教程中,您將學習如何
主成分分析 (PCA) 是一種統計方法,用於提取資料集中最重要的特徵。
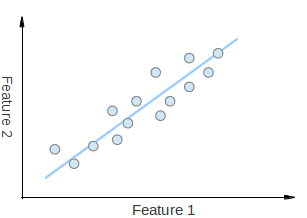
考慮圖中的一組二維點。每個維度對應一個您感興趣的特徵。有人可能會爭辯說這些點是隨機排列的。然而,如果您仔細觀察,會發現存在一個難以忽視的線性模式(由藍線指示)。PCA 的一個關鍵點是降維。降維是減少給定資料集維度數量的過程。例如,在上述情況下,可以將點集近似為一條直線,從而將給定點的維度從二維降到一維。
此外,您還可以看到這些點沿藍線的變化最大,比沿特徵 1 軸或特徵 2 軸的變化更大。這意味著如果您知道點沿藍線的位置,您將比只知道點在特徵 1 軸或特徵 2 軸上的位置擁有更多的資訊。
因此,PCA 允許我們找到資料變化最大的方向。實際上,對圖中點集執行 PCA 的結果是兩個向量,稱為特徵向量,它們是資料集的主成分。
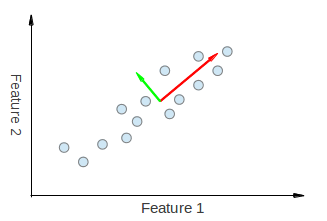
每個特徵向量的大小編碼在相應的特徵值中,並指示資料沿主成分變化的程度。特徵向量的起點是資料集中所有點的中心。將 PCA 應用於 N 維資料集會得到 N 個 N 維特徵向量、N 個特徵值和 1 個 N 維中心點。理論夠了,讓我們看看如何將這些思想付諸程式碼。
目標是將給定維度為 p 的資料集 X 轉換為維度更小 L 的替代資料集 Y。等效地,我們正在尋找矩陣 Y,其中 Y 是矩陣 X 的 Karhunen–Loève 變換 (KLT)
\[ \mathbf{Y} = \mathbb{K} \mathbb{L} \mathbb{T} \{\mathbf{X}\} \]
組織資料集
假設您有一個包含 p 個變數觀測值的資料集,並且您希望減少資料,使得每個觀測值僅用 L 個變數描述,其中 L < p。進一步假設資料排列為一組 n 個數據向量 \( x_1...x_n \),其中每個 \( x_i \) 代表 p 個變數的單個分組觀測值。
計算經驗均值
將計算出的均值放入一個維度為 \( p\times 1 \) 的經驗均值向量 u 中。
\[ \mathbf{u[j]} = \frac{1}{n}\sum_{i=1}^{n}\mathbf{X[i,j]} \]
計算與均值的偏差
均值減法是尋找使資料近似的均方誤差最小化的主成分基的解決方案中不可或缺的一部分。因此,我們透過以下方式對資料進行中心化處理:
將減去均值後的資料儲存在 \( n\times p \) 矩陣 B 中。
\[ \mathbf{B} = \mathbf{X} - \mathbf{h}\mathbf{u^{T}} \]
其中 h 是一個所有元素為 1 的 \( n\times 1 \) 列向量
\[ h[i] = 1, i = 1, ..., n \]
找到協方差矩陣
透過矩陣 B 與自身的外積找到 \( p\times p \) 經驗協方差矩陣 C
\[ \mathbf{C} = \frac{1}{n-1} \mathbf{B^{*}} \cdot \mathbf{B} \]
其中 * 是共軛轉置運算子。請注意,如果 B 完全由實陣列成(許多應用中都是如此),則“共軛轉置”與常規轉置相同。
找到協方差矩陣的特徵向量和特徵值
計算使協方差矩陣 C 對角化的特徵向量矩陣 V
\[ \mathbf{V^{-1}} \mathbf{C} \mathbf{V} = \mathbf{D} \]
其中 D 是 C 的特徵值的對角矩陣。
矩陣 D 將採用 \( p \times p \) 對角矩陣的形式
\[ D[k,l] = \left\{\begin{matrix} \lambda_k, k = l \\ 0, k \neq l \end{matrix}\right. \]
這裡,\( \lambda_j \) 是協方差矩陣 C 的第 j 個特徵值
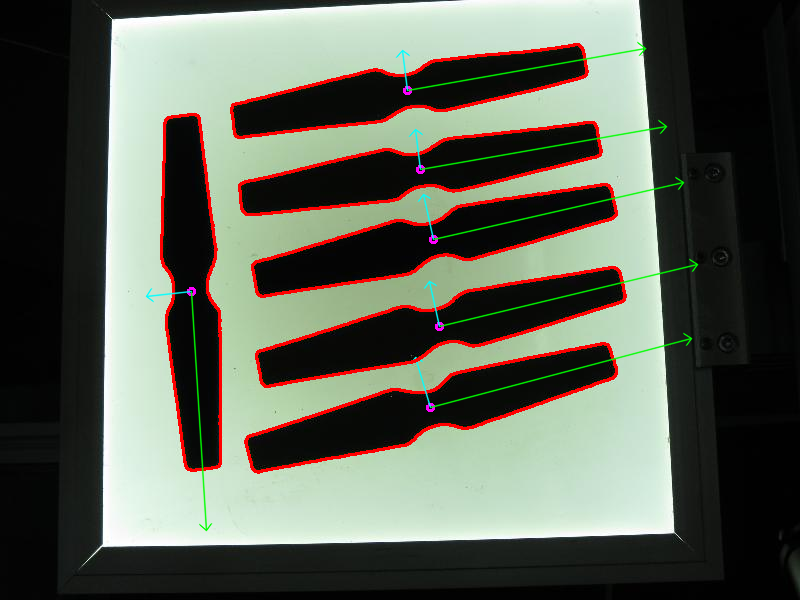
在這裡,我們應用必要的預處理程式,以便能夠檢測感興趣的物件。
然後透過大小查詢和過濾輪廓,並獲取剩餘輪廓的方向。
透過呼叫 getOrientation() 函式來提取方向,該函式執行所有 PCA 過程。
首先,資料需要排列成大小為 n x 2 的矩陣,其中 n 是我們擁有的資料點數量。然後我們可以執行 PCA 分析。計算出的均值(即質心)儲存在 cntr 變數中,特徵向量和特徵值儲存在相應的 std::vector 中。
最終結果透過 drawAxis() 函式視覺化,其中主成分以線條繪製,每個特徵向量乘以其特徵值並平移到均值位置。
該程式碼開啟一幅影像,查詢檢測到的感興趣物件的方向,然後透過繪製檢測到的感興趣物件的輪廓、中心點以及與提取方向相關的 x 軸和 y 軸來視覺化結果。