|
OpenCV 4.12.0
開源計算機視覺
|
載入中...
搜尋中...
無匹配項
|
OpenCV 4.12.0
開源計算機視覺
|
使用弱分類器增強級聯包括兩個主要階段:訓練階段和檢測階段。使用基於HAAR或LBP模型的檢測階段在物件檢測教程中有所描述。本文件概述了訓練您自己的弱分類器增強級聯所需的功能。本指南將引導您完成所有不同階段:收集訓練資料、準備訓練資料以及執行實際的模型訓練。
為支援本教程,將使用幾個OpenCV官方應用程式:opencv_createsamples、opencv_annotation、opencv_traincascade和opencv_visualisation。
為了訓練一個弱分類器增強級聯,我們需要一組正樣本(包含您要檢測的實際物件)和一組負影像(包含您不想檢測的所有內容)。負樣本集必須手動準備,而正樣本集則使用opencv_createsamples應用程式建立。
負樣本取自任意不包含您要檢測的物件的影像。這些用於生成樣本的負影像應列在一個特殊的負影像檔案中,每行包含一個影像路徑(可以是絕對路徑或相對路徑)。請注意,負樣本和樣本影像也稱為背景樣本或背景影像,在本檔案中可互換使用。
描述的影像尺寸可能不同。但是,每張影像的大小應等於或大於所需的訓練視窗大小(這對應於模型尺寸,通常是您物件的平均大小),因為這些影像將用於將給定的負影像子取樣成幾個具有該訓練視窗大小的影像樣本。
此類負描述檔案示例
目錄結構
檔案 bg.txt
您的負視窗樣本集將用於告訴機器學習步驟(在本例中為增強)在嘗試查詢您感興趣的物件時,不應尋找什麼。
正樣本由opencv_createsamples應用程式建立。它們被增強過程用於定義模型在嘗試查詢您感興趣的物件時應實際查詢什麼。該應用程式支援兩種生成正樣本資料集的方式。
雖然第一種方法對於固定物件(如非常剛性的徽標)效果良好,但對於不那麼剛性的物件,它很快就會失效。在這種情況下,我們建議使用第二種方法。網路上許多教程甚至指出,100張真實物件影像可以透過opencv_createsamples應用程式生成比1000張人工生成正樣本更好的模型。但是,如果您確實決定採用第一種方法,請記住一些事項
第一種方法採用一個單一的物件影像(例如公司徽標),並透過隨機旋轉物件、改變影像強度以及將影像放置在任意背景上,從給定的物件影像建立大量正樣本。隨機性的數量和範圍可以透過opencv_createsamples應用程式的命令列引數控制。
命令列引數
-vec <vec_file_name> :包含用於訓練的正樣本的輸出檔名稱。-img <image_file_name> :源物件影像(例如,公司徽標)。-bg <background_file_name> :背景描述檔案;包含用作物件隨機失真版本背景的影像列表。-num <number_of_samples> :要生成的正樣本數量。-bgcolor <background_color> :背景顏色(目前假定為灰度影像);背景顏色表示透明顏色。由於可能存在壓縮偽影,可以透過-bgthresh指定顏色容差量。在bgcolor-bgthresh和bgcolor+bgthresh範圍內的所有畫素都將被解釋為透明。-bgthresh <background_color_threshold>-inv :如果指定,顏色將被反轉。-randinv :如果指定,顏色將隨機反轉。-maxidev <max_intensity_deviation> :前景樣本中畫素的最大強度偏差。-maxxangle <max_x_rotation_angle> :繞x軸的最大旋轉角度,必須以弧度給出。-maxyangle <max_y_rotation_angle> :繞y軸的最大旋轉角度,必須以弧度給出。-maxzangle <max_z_rotation_angle> :繞z軸的最大旋轉角度,必須以弧度給出。-show :有用的除錯選項。如果指定,將顯示每個樣本。按Esc鍵將繼續樣本建立過程,而不顯示每個樣本。-w <sample_width> :輸出樣本的寬度(以畫素為單位)。-h <sample_height> :輸出樣本的高度(以畫素為單位)。以這種方式執行opencv_createsamples時,建立樣本物件例項的過程如下:給定源影像會隨機繞所有三個軸旋轉。選擇的角度受-maxxangle、-maxyangle和-maxzangle限制。然後,強度在[bg_color-bg_color_threshold; bg_color+bg_color_threshold]範圍內的畫素被解釋為透明。白噪聲被新增到前景的強度中。如果指定了-inv鍵,則前景畫素強度將被反轉。如果指定了-randinv鍵,則演算法會隨機選擇是否對該樣本應用反轉。最後,獲得的影像被放置在背景描述檔案中的任意背景上,調整到-w和-h指定的所需大小,並存儲到由-vec命令列選項指定的vec檔案中。
正樣本也可以從以前標記的影像集合中獲取,這是構建魯棒物件模型的首選方式。此集合由類似於背景描述檔案的文字檔案描述。此檔案的每一行對應一張影像。該行的第一個元素是檔名,後跟物件標註的數量,再後跟描述物件邊界矩形座標(x,y,寬度,高度)的數字。
描述檔案示例
目錄結構
檔案 info.dat
影像 img1.jpg 包含一個物件例項,其邊界矩形座標為:(140, 100, 45, 45)。影像 img2.jpg 包含兩個物件例項。
為了從這樣的集合中建立正樣本,應指定-info引數而不是-img
-info <collection_file_name> :標記影像集合的描述檔案。請注意,在這種情況下,-bg、-bgcolor、-bgthreshold、-inv、-randinv、-maxxangle、-maxyangle、-maxzangle等引數將被忽略,不再使用。在這種情況下,樣本建立方案如下:從給定影像中透過裁剪提供的邊界框來獲取物件例項。然後它們被調整到目標樣本大小(由-w和-h定義),並存儲在由-vec引數定義的輸出vec檔案中。不應用任何失真,因此唯一影響的引數是-w、-h、-show和-num。
建立-info檔案的手動過程也可以透過使用opencv_annotation工具來完成。這是一個開源工具,用於在任何給定影像中直觀地選擇物件例項的感興趣區域。以下小節將更詳細地討論如何使用此應用程式。
-vec、-w 和 -h 引數。opencv/data/vec_files/trainingfaces_24-24.vec找到。它可用於訓練人臉檢測器,視窗大小為:-w 24 -h 24。自OpenCV 3.x以來,社群一直提供並維護一個開源標註工具,用於生成-info檔案。如果OpenCV應用程式已構建,則可以透過命令opencv_annotation訪問該工具。
使用該工具非常簡單。該工具接受幾個必需引數和一些可選引數
--annotations (必需) :註釋txt檔案的路徑,您希望在此儲存註釋,然後將其傳遞給-info引數 [示例 - /data/annotations.txt]--images (必需) :包含您物件影像的資料夾路徑 [示例 - /data/testimages/]--maxWindowHeight (可選) :如果輸入影像的高度大於此處給定的解析度,則使用--resizeFactor調整影像大小以便於標註。--resizeFactor (可選) :使用--maxWindowHeight引數時用於調整輸入影像大小的因子。請注意,可選引數只能一起使用。以下是一個可用的命令示例
此命令將彈出一個視窗,其中包含第一張影像和您的滑鼠游標,用於標註。關於如何使用標註工具的影片可以在這裡找到。基本上有幾個按鍵會觸發一個動作。滑鼠左鍵用於選擇物件的第一個角,然後持續繪製直到您滿意,並在註冊第二次滑鼠左鍵點選時停止。每次選擇後,您有以下選擇
c :確認標註,將標註變為綠色並確認已儲存d :從標註列表中刪除最後一個標註(便於刪除錯誤標註)n :繼續到下一張影像ESC :這將退出標註軟體最後,您將得到一個可用的標註檔案,可以將其傳遞給opencv_createsamples的-info引數。
下一步是基於預先準備好的正負資料集,實際訓練弱分類器的增強級聯。
opencv_traincascade應用程式的命令列引數按用途分組
-data <cascade_dir_name> :訓練好的分類器應儲存的位置。此資料夾應事先手動建立。-vec <vec_file_name> :包含正樣本的vec檔案(由opencv_createsamples工具建立)。-bg <background_file_name> :背景描述檔案。這是包含負樣本影像的檔案。-numPos <number_of_positive_samples> :每個分類器階段訓練中使用的正樣本數量。-numNeg <number_of_negative_samples> :每個分類器階段訓練中使用的負樣本數量。-numStages <number_of_stages> :要訓練的級聯階段數量。-precalcValBufSize <precalculated_vals_buffer_size_in_Mb> :預計算特徵值緩衝區大小(Mb)。分配的記憶體越多,訓練過程越快,但請記住,-precalcValBufSize和-precalcIdxBufSize的總和不應超過可用系統記憶體。-precalcIdxBufSize <precalculated_idxs_buffer_size_in_Mb> :預計算特徵索引緩衝區大小(Mb)。分配的記憶體越多,訓練過程越快,但請記住,-precalcValBufSize和-precalcIdxBufSize的總和不應超過可用系統記憶體。-baseFormatSave :此引數在Haar-like特徵的情況下是實際的。如果指定,級聯將以舊格式儲存。這僅用於向後相容性,並允許仍在使用舊棄用介面的使用者,至少可以使用新介面訓練模型。-numThreads <max_number_of_threads> :訓練期間使用的最大執行緒數。請注意,實際使用的執行緒數可能更少,具體取決於您的機器和編譯選項。預設情況下,如果您的OpenCV是在支援TBB的情況下構建的(此最佳化需要TBB支援),則會選擇最大可用執行緒數。-acceptanceRatioBreakValue <break_value> :此引數用於確定模型應學習的精確程度以及何時停止。一個好的指導方針是訓練不超過10e-5,以確保模型不會在您的訓練資料上過擬合。預設情況下,此值設定為-1以停用此功能。-stageType <BOOST(預設)> :階段型別。目前僅支援增強分類器作為階段型別。-featureType<{HAAR(預設), LBP}> :特徵型別:HAAR - Haar-like特徵,LBP - 區域性二值模式。-w <sampleWidth> :訓練樣本的寬度(畫素)。必須與訓練樣本建立(opencv_createsamples工具)時使用的值完全相同。-h <sampleHeight> :訓練樣本的高度(畫素)。必須與訓練樣本建立(opencv_createsamples工具)時使用的值完全相同。-bt <{DAB, RAB, LB, GAB(預設)}> :增強分類器型別:DAB - 離散AdaBoost,RAB - 真實AdaBoost,LB - LogitBoost,GAB - Gentle AdaBoost。-minHitRate <min_hit_rate> :分類器每個階段的最小期望命中率。總命中率可以估計為 (min_hit_rate ^ number_of_stages),[289] §4.1。-maxFalseAlarmRate <max_false_alarm_rate> :分類器每個階段的最大期望誤報率。總誤報率可以估計為 (max_false_alarm_rate ^ number_of_stages),[289] §4.1。-weightTrimRate <weight_trim_rate> :指定是否應使用修剪及其權重。一個不錯的選擇是0.95。-maxDepth <max_depth_of_weak_tree> :弱樹的最大深度。一個不錯的選擇是1,即樹樁的情況。-maxWeakCount <max_weak_tree_count> :每個級聯階段的弱樹最大數量。增強分類器(階段)將擁有達到給定-maxFalseAlarmRate所需的弱樹數量(<=maxWeakCount)。-mode <BASIC (預設) | CORE | ALL> :選擇訓練中使用的Haar特徵集型別。BASIC只使用直立特徵,而ALL使用直立和45度旋轉特徵的完整集。更多詳情請參見[170]。當opencv_traincascade應用程式完成工作後,訓練好的級聯將儲存在-data資料夾中的cascade.xml檔案中。此資料夾中的其他檔案是為了應對訓練中斷而建立的,因此您可以在訓練完成後刪除它們。
訓練完成,您可以測試您的級聯分類器了!
有時視覺化訓練好的級聯可能很有用,可以檢視它選擇了哪些特徵以及其階段有多複雜。為此,OpenCV提供了一個opencv_visualisation應用程式。該應用程式有以下命令
--image (必需) :物件模型的參考影像路徑。這應該是一個標註,其尺寸為[-w,-h],與傳遞給opencv_createsamples和opencv_traincascade應用程式的尺寸相同。--model (必需) :訓練好的模型的路徑,該模型應位於傳遞給opencv_traincascade應用程式的-data引數的資料夾中。--data (可選) :如果提供了資料資料夾(必須事先手動建立),則會儲存階段輸出和特徵影片。下面是一個示例命令:
當前視覺化工具的一些限制
--image引數。在安吉麗娜·朱莉的給定視窗上執行的HAAR/LBP人臉模型示例,該視窗經過了與級聯分類器檔案相同的預處理——>24x24畫素影像、灰度轉換和直方圖均衡化
製作了一個影片,其中每個階段的每個特徵都進行了視覺化

每個階段都作為影像儲存,以便將來驗證特徵
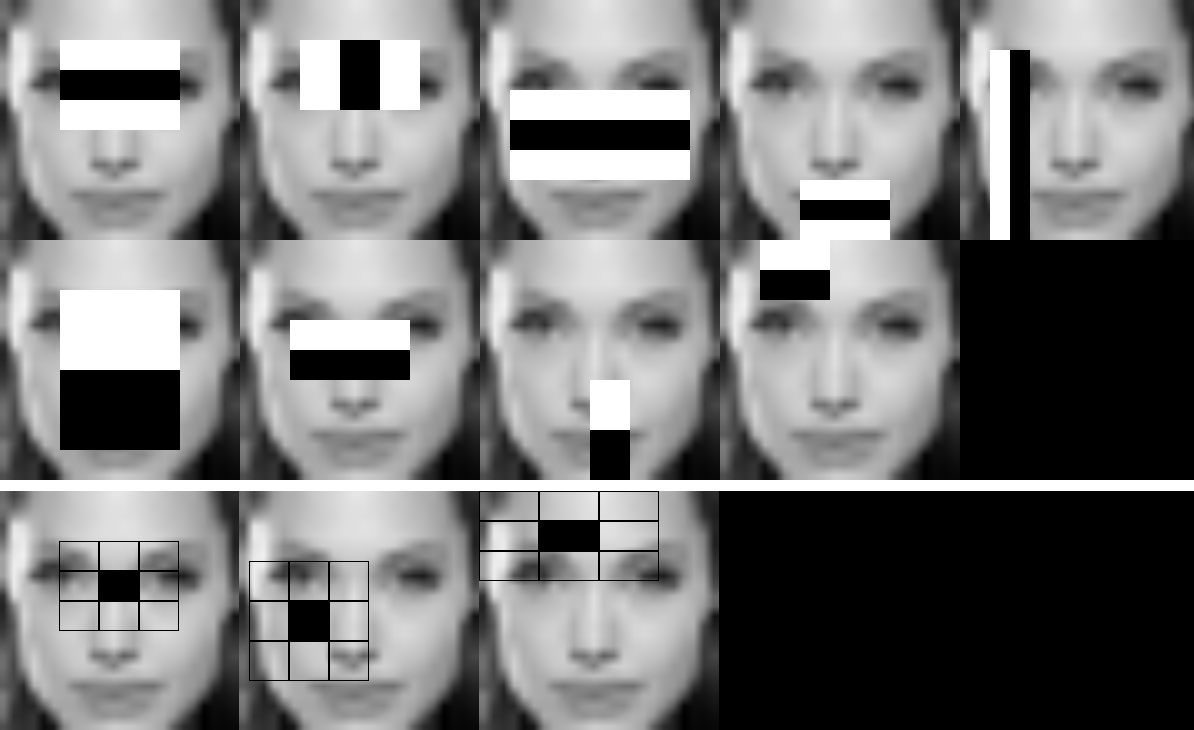
此作品由StevenPuttemans為OpenCV 3 Blueprints建立,Packt Publishing同意將其整合到OpenCV中。